

Ideas, información y conocimientos compartidos por el equipo
de Investigación, Desarrollo e Innovación de BASE4 Security.
Ideas, información y conocimientos compartidos por el equipo
de Investigación, Desarrollo e Innovación de BASE4 Security.

COMPARTIR
Datos de flujo en servidores
Cuando se habla de datos de flujo (netflow, sflow, jflow, IPFIX) inmediatamente vienen a la mente las estadísticas o el resumen de las conexiones que transitan a través de equipos como conmutadores, enrutadores y firewalls. De hecho, estos son los lugares más comunes para capturar datos de flujo/tráfico y, probablemente, estos lugares contendrán la mayor cantidad de datos relevantes, además de ser donde hay una mayor posibilidad de obtener más visibilidad con respecto a la red, sin embargo, capturando esta información en los servidores también es posible y puede ser útil para el seguimiento y la visibilidad en algunos casos.
Este tipo de estrategia puede ser útil para segmentos de red donde no hay equipos con capacidad nativa para exportar datos de flujo, o para entregar fácilmente una captura completa en el formato pcap, pero también se puede utilizar para monitorear redes domésticas, como es el caso del pequeño laboratorio que se mostrará en este artículo. Este monitoreo, entre otras ventajas, puede ayudar a comprender cómo fluyen los datos dentro de la red, encontrar problemas (troubleshooting) y, por supuesto, brindar un poco más de visibilidad para ayudar también a detectar actividades inusuales, sospechosas o maliciosas.
Como se mencionó en el artículo anterior sobre Datos de flujo, se necesitan 3 elementos para recopilar y analizar estos datos: un equipo exportador, un colector y un analizador. En este escenario hipotético, haremos todo en un solo dispositivo, dejando el software de análisis para un próximo artículo. El enfoque aquí es cómo obtener los datos y analizarlos un poco más crudos.
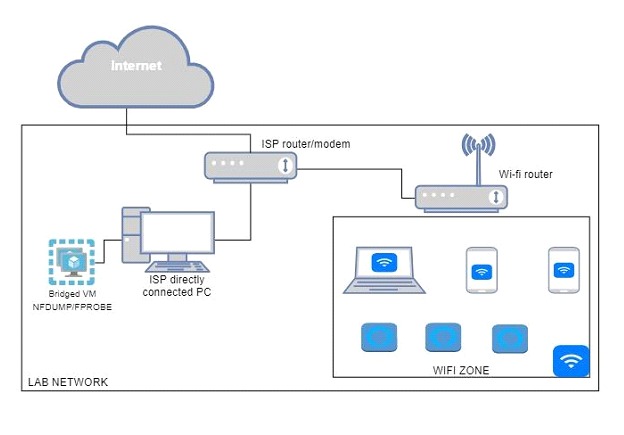
Información sobre el laboratorio.
Para llevar a cabo esta labor de exportación y recopilación se utilizarán dos herramientas de código abierto: nfdump y fprobe, dentro de una máquina virtual con Kali Linux instalado. Debe configurar la máquina virtual para permitir que su interfaz de red entre en modo promiscuo. En este escenario, la interfaz en modo promiscuo te permitirá ver todo el tráfico, ya que es una red doméstica sin segmentación: esto incluye el tráfico que no está destinado a la VM o la interfaz del host, como las comunicaciones entre otros dispositivos en la red.
Es posible que esta práctica de laboratorio se reproduzca en otras distribuciones de Linux e incluso en máquinas Windows, utilizando conceptos y herramientas similares. A continuación, un dibujo de la estructura de la red doméstica donde se realizarán las pruebas.
Primero, es necesario buscar e instalar las utilidades mencionadas anteriormente, nfdump fprobe. Por motivos de organización, la configuración de este software se tratará en dos secciones diferentes de este artículo. Nota: En los siguientes ejemplos, ambos programas se instalaron usando el administrador de paquetes (apt – como en Debian) y no se encontraron problemas en la operación, sin embargo, es interesante notar que la instalación se puede hacer manualmente usando el código fuente de los desarrolladores
Configuración del servidor para la recopilación de datos de transmisión
NFDUMP será responsable de capturar/recolectar estos datos. En resumen, según la página de GitHub del proyecto, se trata de un paquete de software de código abierto que permite recolectar , procesar y analizar datos de flujo de red enviados por dispositivos compatibles. Tenga en cuenta que la suite nfdump no será nuestro software de exportación de datos de flujo, sino el de recopilación.

Después de instalar el nfdump, la utilidad estará disponible nfcapd, que tiene la capacidad de funcionar como daemon, y permitirá la apertura de un socket para recibir la transmisión de datos. Para configurar la utilidad para recibir datos de transmisión, debe ejecutar el siguiente comando:

Dónde:
⦁ -I “Exporter_#1”: definir una string identificación para el archivo de estadísticas.
⦁ -D: pasa la ejecución a un segundo plano
⦁ -p: definir un puerto udp el que el colector escuchará
⦁ -w: define el directorio donde se almacenarán los archivos flow
⦁ -S1: define un esquema de almacenamiento en subdirectorios, en el siguiente formato: %Y/%m/%d año/mes/día (buscar en man nfcapd(1) para más opciones, el valor predeterminado es 0, sin subdirectorios).
Hecho esto, el socket abrirá en el servidor, donde se pueden señalar los datos de transmisión de cualquier fuente. Recordando: en este ejemplo, todos los elementos estarán presentes en un solo servidor, y solo una instancia del nfcapd. Es importante mencionar que esta utilidad admite varias instancias de sí misma, lo que permite enviar flujos de datos desde diferentes exportadores (conmutadores, enrutadores, firewalls y ¿por qué no servidores?) y separarlos por puerto de destino en el servidor y por directorios, por ejemplo, mejor organización de datos.
Usando el comando netstat -planu es posible identificar el servicio en ejecución y su respectivo PID.
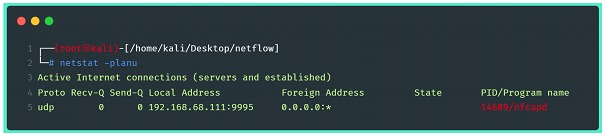
Con esta configuración, el servidor ya puede recibir y transmitir datos en la dirección y el puerto que se muestran en la imagen. El siguiente paso es configurarlo para capturar y exportar los datos del flujo.
Configuración del servidor para exportar datos de transmisión
Como se mencionó anteriormente, el software utilizado para exportar los datos de flujo será sonda, una herramienta de código abierto, que se ejecuta en sistemas basados en Linux para un monitoreo de red muy ligero, que se utiliza para recopilar y exportar datos de flujo de red en tiempo real. A falta de una descripción más completa en las páginas del manual/desarrollador, se le pidió al modelo de inteligencia artificial “ChatGPT” que describiera las características fprobe, y el siguiente texto fue el resultado:
“fprobe funciona escuchando el tráfico de la red en una interfaz determinada y generando datos de flujo basados en la información recopilada. Puede recopilar datos a través de una variedad de protocolos de red, incluidos TCP, UDP e ICMP. Los datos recopilados por fprobe incluyen información como las direcciones IP de origen y destino, los puertos de origen y destino y la cantidad de datos transferidos.
Una de las características clave de fprobe es su capacidad para exportar datos de flujo a varios recopiladores y analizadores de flujo, como la popular herramienta de análisis de tráfico de red, ntopng. fprobe puede exportar datos en diferentes formatos, incluidos NetFlow e IPFIX.
Otras características de fprobe incluyen:
⦁ Bajo uso de CPU y memoria, lo que lo hace ideal para usar en dispositivos de bajo consumo
⦁ Soporte para múltiples interfaces y direcciones IPv6
⦁ Opciones configurables de filtrado de paquetes para capturar tipos específicos de tráfico
⦁ La capacidad de generar informes en múltiples formatos, incluidos ASCII y HTML”
Fprobe se encargará de hacer que la interfaz de red entre en modo promiscuo, escuchando el tráfico y exportándolo al colector pre configurado. Para hacerlo, deberá seguir algunos pasos, el primero de los cuales es instalar la utilidad:

Una vez instalado, fprobe ahora está listo para ser utilizado. Hay dos formas de hacerlo funcionar: la primera es ejecutar el programa como un comando shell, el problema de esto es que siempre será necesario ejecutarlo manualmente, o incluir el comando en algún script inicialización, programación o similar. La otra forma es cambiar el archivo de configuración y hacer que se ejecute como un servicio. Ambos caminos fprobe se ejecuta en segundo plano, conectado a un sumidero que está listo para recibir la transmisión de datos.
Debajo, la ejecución del comando fprobe:

Dónde:
⦁ -i eth0 – la interfaz que será el destino de la exportación de datos de flujo
⦁ dirección :puerto del servicio de recogida
Nota fprobe, tanto en su versión “servicio” como en su versión ejecutable en línea de comandos, cuenta con varias opciones de funcionamiento y filtrado. Los filtros fprobe exactamente iguales a los de tcpdump y puede ser usados para seleccionar datos, protocolos, direcciones, interfaces, puertos, etc. En este ejemplo estamos usando la forma más simple de ejecutar fprobe.
Una vez ejecutado, es posible monitorear los mensajes del núcleo linux para identificar si hubo algún error en la ejecución, o si el comando se ejecutó correctamente:

Otra posible verificación es usar el comando netstat para visualizar la conexión entre exportador y recaudador establecida:
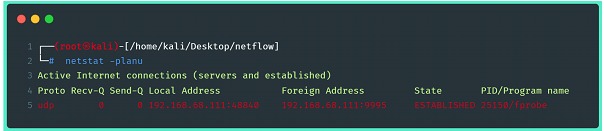
Una vez establecida la conexión entre el colector y el exportador, los datos de flujo comienzan a escribirse en el directorio previamente indicado al configurar el colector.
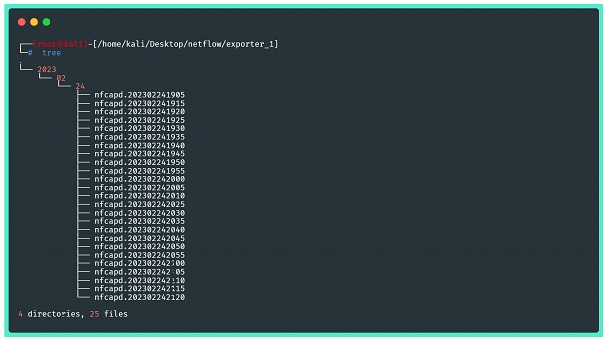
Volviendo a la suite nfdump, para verificar la consistencia de los datos de flujo almacenados, podemos usar los comandos de análisis proporcionados por el software.
En las imágenes a continuación, hay algunos ejemplos, pero es muy recomendable que consulte las páginas de ayuda de la utilidad, así como sus manuales para aplicar filtros y manejar estadísticas. La primera imagen muestra un resumen estadístico de los datos capturados, conteniendo información de todo lo enviado por el exportador.
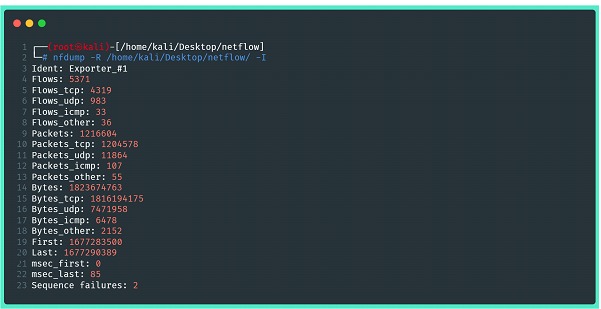
⦁ -R: lee el contenido de netflow de una secuencia de archivos y subdirectorios del directorio indicado;
⦁ -I: Imprime información de resumen de estadísticas de flujo neto para un archivo o rango de archivos (-r o -R)
La siguiente imagen trae información sobre los datos transmitidos en el formato extendido, proporcionada por el nfdump sin ningún tipo de filtro. Podemos ver información como marcas de tiempo, direcciones IP y puertos de origen y destino, cantidad de paquetes, bytes, paquetes y bytes por segundo, y al final, un resumen:
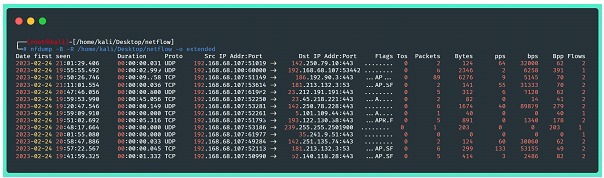
Dónde:
⦁ -B: Agrega los flujos bidireccionalmente (considera tráfico de ida y vuelta);
⦁ -R: lee el contenido de netflow de una secuencia de archivos y subdirectorios del directorio indicado;
⦁ -o extended: indica el formato de salida (raw, line, long, extended, csv, json...)
Nota importante: si no se especifica nada en la configuración nfcap, el recopilador "escuchará" los datos de flujo durante ciclos de 300 segundos, y solo al final de cada ciclo se escribirán nuevos archivos en el disco. Por lo tanto, no hay razón para desesperarse si la verificación descrita en la imagen de arriba no produce ningún resultado.
De acuerdo a la necesidad, como se mencionó anteriormente, es posible hacer fprobe se ejecuta como un servicio cambiando su archivo de configuración. En una instalación estándar víaapto (para distribuciones me gusta Debian) el archivo de configuración se encuentra en /etc/default/fprobe, y su contenido es sumamente intuitivo:

Las opciones proporcionadas por el comando fprobe, incluido el filtrado, debe incluirse en la sección “OTHER_ARGS=”. Después de cambiar correctamente el archivo de configuración, el siguiente paso es activar fprobe a través de systemctl y si es necesario, incluirlo en el systemd para el arranque automático.
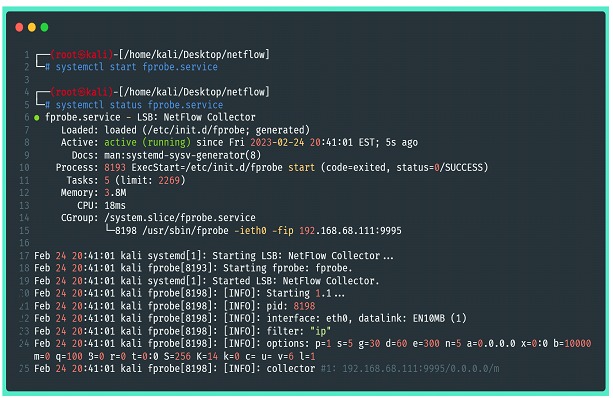
Una vez hecho esto, es posible volver a los pasos anteriores para verificar si el servicio está generando correctamente los archivos con los datos de flujo.
Conclusiones:
El propósito de desarrollar contenido como este es mostrar que capturar datos de flujo en los servidores es una tarea extremadamente simple de realizar y que puede brindar buena información para las operaciones de monitoreo. Este tipo de recopilación cumple muy bien lo que promete y logra efectivamente el objetivo de brindar un poco más de visibilidad y comprensión sobre la red monitoreada en forma de estadísticas a un costo muy bajo: siempre es importante recordar que no hay datos sin procesar. Aquí, solo metadatos, lo que hace que la operación sea muy liviana y puede ayudar a ahorrar espacio en disco y procesamiento.
Para tener una idea de la cantidad de datos generados en términos de espacio en disco, el entorno de laboratorio fue monitoreado durante casi 72 horas ininterrumpidas y terminó ocupando aproximadamente 3,5 MB. Considerando que es una red doméstica de pequeño tamaño, con poco más de 10 dispositivos conectados, pero con un buen flujo de información, con largos periodos de streams de video, reuniones en línea y otras conexiones, pudimos probar los ahorros en términos de volumen de datos, especialmente en comparación con otras formas de captura de tráfico.

En este laboratorio se logró aumentar la visibilidad de una red doméstica. La idea inicial era comprender mejor el funcionamiento de la red y poder monitorear las actividades que realizan los dispositivos IoT, como los interruptores inteligentes y las bombillas que están conectadas a Internet.
A continuación, como último ejemplo, una más de las funciones de la herramienta nfdump, que es mostrar las estadísticas de datos de flujo divididas por "campos" presentes en el flow.
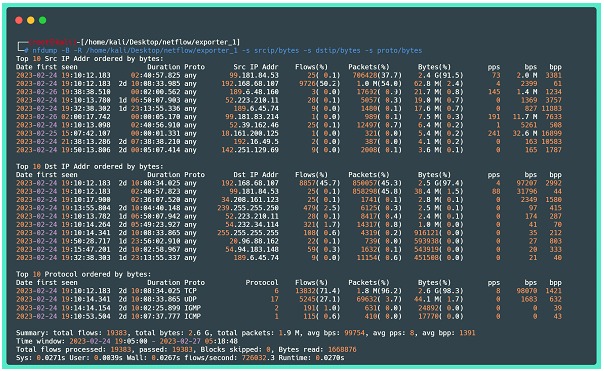
Dónde:
⦁ -B: Agrega los flujos bidireccionalmente (considera tráfico de ida y vuelta);
⦁ -R: lee el contenido de netflow de una secuencia de archivos y subdirectorios del directorio indicado;
⦁ -s:Muestra un Top 10 de las estadísticas solicitadas, en el ejemplo anterior se destacan las IP de origen ordenadas por bytes, las IP de destino por bytes y los protocolos por bytes. Cabe señalar que por defecto se muestra el top 10, pero este número se puede cambiar agregando la opción -n.
Este escenario es perfectamente transportable a un entorno mayor y aplicable en lugares donde la visibilidad, el presupuesto y la capacidad de seguimiento son limitados. El próximo post, el último de esta serie, abordará una aplicación más profesional de este tipo de monitorización, utilizando una herramienta de análisis con mayor capacidad de visualización de datos históricos.