

Ideias, informações e conhecimentos compartilhados pela equipe
de Investigação, Desenvolvimento e Inovação da BASE4 Security..
Ideias, informações e conhecimentos compartilhados pela equipe
de Investigação, Desenvolvimento e Inovação da BASE4 Security.

COMPARTILHAR
Dados de fluxo em servidores
Quando se fala em dados de fluxo (netflow, sflow, jflow, IPFIX) logo vem à mente as estatísticas ou resumo das conexões que transitam por equipamentos como switches, roteadores e firewalls. De fato, esses são os locais mais comuns de captura de dados de fluxo/tráfego e, provavelmente, nesses locais estarão a maior quantidade de dados relevantes, além de ser onde há maior possibilidade de obter mais visibilidade a respeito da rede, porém, capturar essas informações em servidores também é possível e pode ser útil para o monitoramento e visibilidade em alguns casos.
Esse tipo de estratégia pode ser útil para segmentos de rede onde não há equipamentos com capacidade nativa de exportar dados de fluxo, ou de entregar facilmente uma captura completa no formato pcap, mas também pode servir para monitoramento de redes domésticas, como é o caso do pequeno laboratório que será mostrado neste artigo. Esse monitoramento, entre outras vantagens, pode ajudar a entender como os dados fluem dentro da rede, encontrar problemas (troubleshooting) e, é claro, entregar um pouco mais de visibilidade para ajudar também na detecção de atividades incomuns, suspeitas ou maliciosas.
Como já foi dito no artigo anterior sobre Dados de Fluxo (link), são necessários 3 elementos para coleta e análise desses dados: um equipamento exportador, um coletor e um analisador. Neste cenário hipotético, faremos tudo em um só equipamento, deixando o software de análise para um artigo futuro. O foco aqui está em como obter os dados e analisá-los de maneira um pouco mais bruta.
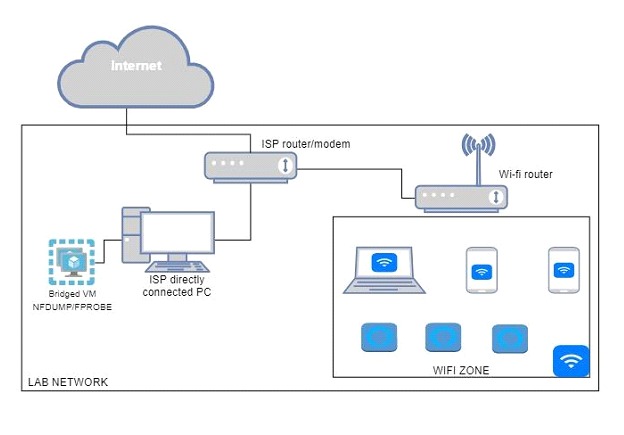
Informações sobre o laboratório
Para realizar este trabalho de exportação e coleta, serão utilizadas duas ferramentas opensource: nfdump e fprobe, dentro de uma máquina virtual com o Kali Linux instalado. É necessário configurar a máquina virtual para permitir que sua interface de rede entre no modo promíscuo. Neste cenário, a interface em modo promíscuo permitirá enxergar todo o tráfego, já que se trata de uma rede doméstica sem segmentação: isso inclui tráfego que não é destinado à interface da VM ou do hospedeiro, como as comunicações entre outros dispositivos na rede.
É possível que este laboratório seja reproduzido em outras distribuições do Linux e até mesmo em máquinas Windows, utilizando os conceitos e ferramentas parecidas. Abaixo, um desenho de como é a estrutura de rede doméstica onde serão realizados os testes.
Primeiramente, é necessário buscar e instalar os utilitários citados anteriormente, nfdump e fprobe. Para fins de organização, a configuração desses softwares será abordada em duas seções diferentes deste artigo. Nota: nos exemplos a seguir, ambos os softwares foram instalados utilizando o gerenciador de pacotes (apt – debian like) e não foram encontrados problemas no funcionamento, porém é interessante destacar que a instalação pode ser feita manualmente utilizando o código fonte dos desenvolvedores.
Configuração do servidor para coleta dos dados de fluxo
O NFDUMP será o responsável pela captura/coleta desses dados. Em poucas palavras, segundo a página do projeto no GitHub, trata-se uma suíte de softwares de código aberto que permite coletar, processar e analisar dados de fluxo de rede enviados por dispositivos compatíveis. Note que a suíte nfdump não será o nosso software de exportação dos dados de fluxo, mas sim o de coleta.

Depois de instalado o nfdump, estará disponível o utilitário nfcapd, que tem a capacidade de funcionar em modo daemon, e permitirá a abertura de um socket para receber os dados de fluxo. Para configurar o utilitário para receber os dados de fluxo, é necessário executar o comando abaixo:

Onde:
⦁ -I “Exporter_#1”: define uma string de identificação para o arquivo de estatísticas
⦁ -D: joga a execução para segundo plano
⦁ -p: define a porta udp na qual o coletor irá escutar
⦁ -w: define o diretório onde serão armazenados os arquivos de flow
⦁ -S1: define um esquema de armazenamento em subdiretórios, no seguinte formato: %Y/%m/%d ano/mês/dia (buscar no man nfcapd(1) para mais opções, o padrão é 0, sem subdiretórios).
Feito isso, o socket será aberto no servidor, para onde os dados de fluxo de qualquer origem podem ser apontados. Relembrando: nesse exemplo, todos os elementos estarão presentes em apenas um servidor, e somente será necessária uma instância do nfcapd. É importante comentar que esse utilitário suporta várias instâncias de si mesmo, tornando possível enviar dados de fluxo de diversos exportadores (switches, roteadores, firewalls e por que não servidores?) diferentes e separá-los por porta de destino no servidor e por diretórios, para melhor organização dos dados.
Utilizando o comando netstat -planu é possível identificar o serviço rodando e seu respectivo PID.
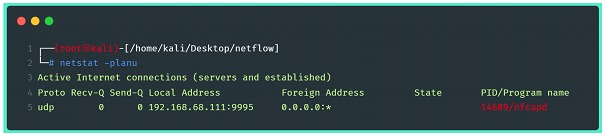
Com essas configurações o servidor já é capaz de receberdados de fluxo no endereço e porta mostrados na imagem. O próximo passo é configurá-lo para capturar e exportar os dados de fluxo.
Configuração do servidor para exportação dos dados de fluxo
Como citado anteriormente, o software utilizado para exportação dos dados de fluxo será o fprobe, uma ferramenta de código aberto, que funciona em sistemas baseados em Linux para um monitoramento de rede bastante leve, utilizada para coletar e exportar dados de fluxo de rede em tempo real. Na falta de uma descrição mais completa nas páginas de manuais/desenvolvedores, foi solicitado ao modelo de inteligência artificial “ChatGPT” que descrevesse as características do fprobe, e o texto abaixo foi o resultado:
“O fprobe funciona ouvindo o tráfego de rede em uma determinada interface e gerando dados de fluxo com base nas informações coletadas. Ele pode coletar dados sobre uma variedade de protocolos de rede, incluindo TCP, UDP e ICMP. Os dados coletados pelo fprobe incluem informações como endereços IP de origem e destino, portas de origem e destino e a quantidade de dados transferidos
Uma das principais características do fprobe é a sua capacidade de exportar dados de fluxo para vários coletores e analisadores de fluxo, como a popular ferramenta de análise de tráfego de rede, o ntopng. O fprobe pode exportar dados em diferentes formatos, incluindo NetFlow e IPFIX.
Outras características do fprobe incluem:
⦁ Baixo uso de CPU e memória, tornando-o ideal para uso em dispositivos de baixa potência
⦁ Suporte a múltiplas interfaces e endereços IPv6
⦁ Opções de filtragem de pacotes configuráveis para capturar tipos específicos de tráfego
⦁ A capacidade de gerar relatórios em vários formatos, incluindo ASCII e HTML”
O fprobe será o responsável por fazer a interface de rede entrar no modo promíscuo, escutar o tráfego e exportá-lo para o coletor pré-configurado.Para isso, será necessário seguir alguns passos, e o primeiro deles é realizar a instalação do utilitário:

Depois de instalado, o fprobe já está pronto para ser utilizado. Há duas maneiras de fazê-lo funcionar: a primeira é executando o programa como um comando no shell, o problema disso é que sempre será necessário executar manualmente, ou incluir o comando em algum script de inicialização, agendamento ou similar. A outra maneira é alterar o arquivo de configuração e fazê-lo executar como um serviço. Ambas as formas farão o fprobe ser executado em segundo plano, conectado a um coletor que esteja pronto para receber os dados de fluxo.
Abaixo, o comando que fará o fprobe rodar instantaneamente no shell:

Onde:
⦁ -i eth0 – a interface que será alvo da exportação dos dados de fluxo
⦁ dirección :porta do serviço de coleta
Nota: o fprobe, tanto em sua versão de “serviço” como em sua versão executada em linha de comando, possui diversas opções de funcionamento e filtragem. Os filtros do fprobe são exatamente os mesmos do tcpdump e podem ser necessários para selecionar dados, protocolos, endereços, interfaces, portas e etc. Neste exemplo estamos utilizando a maneira mais simples de execução do fprobe.
Depois de executado, é possível monitorar as mensagens do kernel Linux para identificar se houve algum erro na execução, ou se o comando foi executado com sucesso:

Outra verificação possível, é utilizar o comando netstat para visualizar a conexão entre exportador e coletor estabelecida:
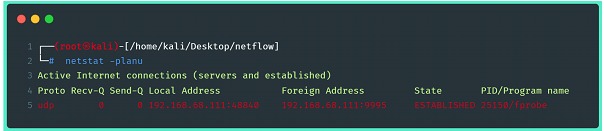
Depois de estabelecida a conexão entre coletor e exportador, os dados de fluxo já começam a ser escritos no diretório apontado anteriormente no momento da configuração do coletor.
Voltando à suíte nfdump, para verificar a consistência dos dados de fluxo armazenados, podemos utilizar os comandos de análise fornecidos pelo software. Nas imagens abaixo, há alguns exemplos, mas é altamente recomendável que sejam consultadas as páginas de ajuda do utilitário, bem como seus manuais para aplicação de filtros e manipulação das estatísticas. A primeira imagem mostra um resumo estatístico dos dados capturados, contendo informações a respeito de tudo que foi enviado pelo exportador.
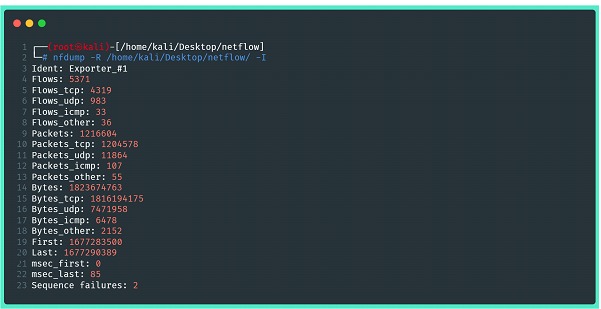
Onde:
⦁ -R: lê o conteúdo netflow de uma sequência de arquivos e subdiretórios do diretório indicado;
⦁ -I: Imprime informações resumidas de estatísticas do fluxo líquido de um arquivo ou intervalo de arquivos (-r ou -R)
A próxima imagem traz informações a respeito dos dados trafegados no formato estendido, fornecido pelo próprio nfdump sem nenhum tipo de filtro. Podemos ver informações como timestamps, endereços de IP e portas de origem e destino, quantidade de pacotes, bytes, pacotes e bytes por segundo, e ao final, um resumo:
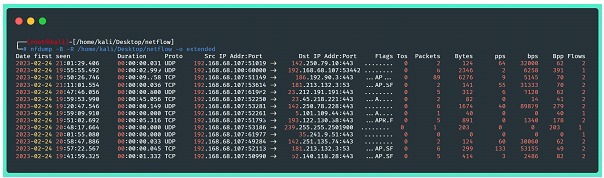
Where:
⦁ -B: Agrega os flows de forma bidirecional (considera ida e volta do tráfego);
⦁ -R: lê o conteúdo netflow de uma sequência de arquivos e subdiretórios do diretório indicado;
⦁ -o extended: indica o formato da saída (raw, line, long, extended, csv, json...)
Nota importante: se nada for especificado na configuração do nfcapd, os dados de fluxo serão “escutados” pelo coletor durante ciclos de 300 segundos, e só ao final de cada ciclo os novos arquivos serão escritos em disco. Portanto, não há motivos para desespero caso a verificação descrita na imagem acima não traga nenhum resultado!
Conforme a necessidade, como dito anteriormente, é possível fazer com que o fprobe funcione como um serviço, alterando seu arquivo de configuração. Numa instalação padrão via apt (para distribuições debian like) o arquivo de configuração está localizado em /etc/default/fprobe , e seu conteúdo é extremamente intuitivo::

As opções fornecidas pelo comando fprobe, inclusive de filtragem, devem ser incluídas na seção “OTHER_ARGS=”. Depois de alterar corretamente o arquivo de configuração, o próximo passo é ativar o serviço do fprobe através do systemctl e se necessário, incluí-lo no systemd para inicialização automática.
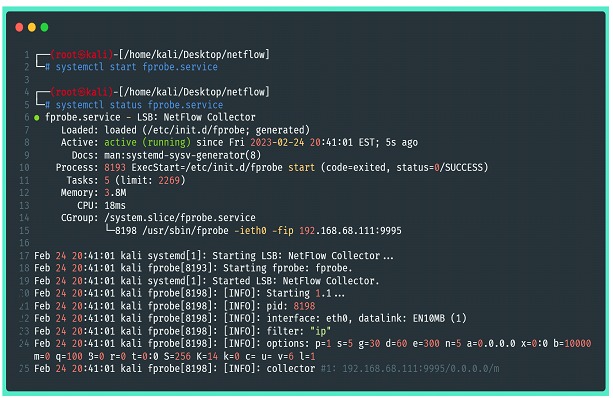
Feito isso, é possível retornar aos passos anteriores para verificar se o serviço está gerando os arquivos com os dados de fluxo corretamente.
Conclusões:
O objetivo de desenvolver um conteúdo como esse é mostrar que a captura dos dados de fluxo em servidores é uma tarefa extremamente simples de ser executada e que pode trazer boas informações para as operações de monitoramento. Esse tipo de coleta cumpre muito bem o que promete e atinge com eficácia o objetivo de entregar um pouco mais de visibilidade e entendimento a respeito da rede monitorada em forma de estatísticas a um custo bastante baixo: é sempre importante lembrar que aqui não há dados brutos, somente metadados, o que deixa a operação bastante leve e pode ajudar a economizar espaço em disco e processamento.
Para se ter uma ideia da quantidade de dados gerados em termos de espaço em disco, o ambiente do laboratório foi monitorado durante praticamente 72 horas ininterruptas e terminou ocupando aproximadamente 3,5 MB. Considerando que se trata de uma rede doméstica de tamanho pequeno, com pouco mais de 10 dispositivos conectados, porém com um bom fluxo de informações, contando com longos períodos de streams de vídeo, reuniões online e outras conexões, conseguimos comprovar a economia em termos de volume de dados, principalmente quando comparado com outras formas de captura de tráfego.

Neste laboratório foi possível aumentar a visibilidade de uma rede doméstica. A ideia inicial era obter maior entendimento do funcionamento da rede e poder monitorar as atividades que realizam os dispositivos IoT como interruptores e lâmpadas inteligentes que estão conectados à internet. Abaixo, como último exemplo, mais uma das funções da ferramenta nfdump, que é mostrar as estatísticas dos dados de fluxo divididos por “campos” presentes nos flows.
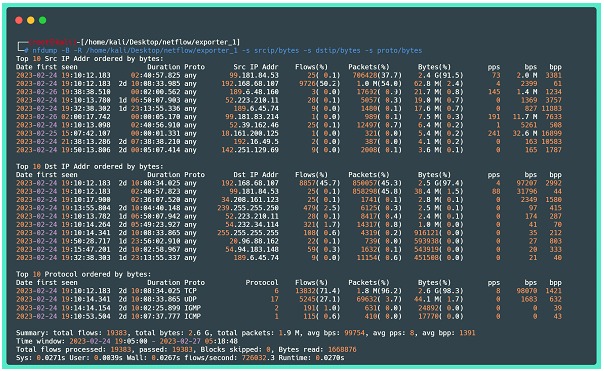
Where:
⦁ -B: Agrega os flows de forma bidirecional (considera ida e volta do tráfego);
⦁ -R: lê o conteúdo netflow de uma sequência de arquivos e subdiretórios do diretório indicado;
⦁ -s: Mostra um Top 10 das estatísticas solicitadas, no exemplo acima estão destacados IPs de origem ordenados por bytes, IPs de destino por bytes, e protocolos por bytes. Cabe destacar que por padrão, é mostrado o top 10, mas esse número pode ser alterado agregando a opção -n.
Esse cenário é perfeitamente transportável para um ambiente maior e aplicável em locais onde a visibilidade, orçamento e capacidade de monitoramento são limitadas. No próximo post, último desta série, será abordada uma aplicação mais profissional deste tipo de monitoramento, utilizando uma ferramenta de análise com maior capacidade de visualização histórica dos dados.