

Ideias, informações e conhecimentos compartilhados pela equipe
de Investigação, Desenvolvimento e Inovação da BASE4 Security..
Ideias, informações e conhecimentos compartilhados pela equipe
de Investigação, Desenvolvimento e Inovação da BASE4 Security.

POR:
Felipe Alves
CYBER SECURITY RESEARCHER & TRAINER
COMPARTILHAR
REFERÊNCIAS
B. Claise, B. Trammell, and P. Aitken, “Specification of the IP Flow Information Export (IPFIX) Protocol for the Exchange of Flow Information,” RFC 7011 (Internet Standard), Internet Engineering Task Force, September 2013. [Online]. Available: http://www.ietf.org/rfc/rfc7011.txt
What is NetFlow? An Overview of the NetFlow Protocol. Disponível em: https://www.kentik.com/kentipedia...
Por que usar dados de fluxo para monitoramento?
No ponto em que estamos localizados na crescente curva de evolução tecnológica e, por consequência, das ameaças digitais, cresce na mesma intensidade a necessidade por visibilidade em relação aos dados que estão passando pelas infraestruturas dos mais variados tipos de organizações. A demanda por essa visibilidade pode esbarrar em diversos aspectos técnicos, que variam desde a necessidade de boas estratégias para posicionamento dos equipamentos de captura até a necessidade por grandes quantidades de hardware para armazenamento e processamento dos dados capturados. Outro item que precisa de atenção é o valor que os dados capturados têm, ou seja, é importante saber se o que está sendo guardado traz de fato a visibilidade e a capacidade de monitoramento almejadas. Dessas ideias, naturalmente surgem algumas perguntas, e em rodas de discussão de Blue Teamers questões que estão sempre presentes são: o que devo capturar? Capturar todo o trafego por menos tempo (devido às limitações de hardware)? Capturar somente os metadados e realizar correlações com os logs disponíveis? Para responder a essas perguntas, somente um bom clichê: É necessário trabalhar com equilíbrio, pois ambas as abordagens trazem visibilidade e têm vantagens e desvantagens.
A princípio é possível pensar que o cenário ideal é ter o tráfego completamente capturado para apoiar as atividades de resposta a incidentes, threat hunting, SOC, CSIRT, etc, uma vez que através da captura completa é possível reconstruir a comunicação entre cliente e servidor e ter uma visão real do que ocorreu, mas, embora isso realmente possa parecer o melhor dos mundos para investigações, a quantidade histórica disponível não vai passar de alguns dias ou semanas, devido à grande quantidade de recursos necessária. Isso se torna um problema quando precisamos investigar algo que ocorreu num período anterior à capacidade histórica, sem considerar os problemas que podem surgir quando se trata de tráfego criptografado. Uma alternativa equilibrada é obter metadados desse tráfego integrados com logs, o que pode cobrir uma boa parte da organização em relação a estatísticas sobre as conexões realizadas entre os utilizadores da infraestrutura.
Dentro deste contexto, o objetivo deste artigo é discutir a segunda opção citada no parágrafo anterior, que é uma abordagem interessante à captura completa de tráfego e que é capaz de entregar boa visibilidade sobre temas como: quem se comunica com quem, quando ocorreu essa comunicação, por quanto tempo e com que frequência. Trata-se de capturar os fluxos de dados, exportá-los e criar métricas de monitoramento baseadas nesses fluxos, através de protocolos como o que a Cisco originalmente deu o nome de NetFlow, e que posteriormente foi “traduzido” para uma versão opensource à qual foi dado o nome de IPFIX. Esse tipo de abordagem pode ser altamente benéfico para o monitoramento contínuo de uma organização, uma vez que possibilita manter rastreabilidade histórica muito maior sobre as comunicações pelo simples fato de que exige menos dos recursos de armazenamento quando comparado com captura completa de tráfego.
Este é o primeiro de uma série de 2 posts sobre esse assunto. Nele vamos definir alguns conceitos e refletir sobre estratégias de monitoramento e, em outro momento, abordaremos ferramentas, técnicas e demonstrações práticas.
O que é Netflow/Fluxo de dados/Flow?
Buscando a informação direto na fonte, a RFC 7011 de 2013 que especifica o protocolo IPFIX, define o fluxo de dados, ou simplesmente flow, como sendo o seguinte: “um conjunto de pacotes IP passando num ponto de observação dentro da rede durante um certo intervalo de tempo, sendo que todos os pacotes que pertencem a um flow em particular têm um conjunto de propriedades em comum.”
As propriedades dos flows, também chamadas de flow-keys são cada campo que: (i) pertencem ao cabeçalho do pacote em si; (ii) são propriedades do pacote, como o tamanho em bytes; (iii) são derivadas da atividade de Tratamento dos Pacotes, como por exemplo o número do Autonomous System (ASN).
Trocando em miúdos, cada flow é um conjunto de pacotes agregados, ou seja, os pacotes não são considerados individualmente, como em uma abordagem de captura completa. É como se as sequências de pacotes tivessem uma espécie de assinatura que é usada para juntar os vários elementos de uma comunicação em um único flow. Os flows contêm metadados valiosos sobre as comunicações e devem ser exportados por algum equipamento por onde o tráfego passa, chamado de ‘exportador’ (normalmente firewalls, switches e roteadores), e coletados para análise posterior.
Ainda segundo a RFC, a coleta desse fluxo serve para fins administrativos ou quaisquer outros, tais quais os citados no início desta publicação, como visibilidade, mas também troubleshooting, detecção de ameaças, monitoramento de performance e, por consequência, segurança!
Metadados
Como dito anteriormente, um equipamento exportador de fluxos identifica um flow como sendo um conjunto de pacotes com características em comum pertencentes a uma determinada comunicação. Essas características contidas nos pacotes são no mínimo: porta da interface de entrada, endereços de IP de origem e destino, portas de origem e destino, protocolo e tipo de serviço. Curiosamente estes também podem ser considerados como os principais atributos da comunicação que serão úteis para análise posterior, sempre lembrando que se trata de metadados, ou seja: o conteúdo dos pacotes não está disponível. Falaremos sobre isso mais tarde.
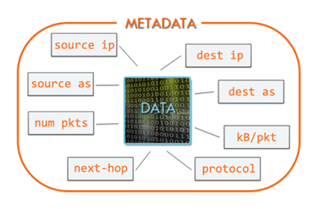
Exportação
Os processos de captura e análise de fluxos dependem basicamente de 3 componentes: um equipamento “exportador”; um equipamento “coletor”; e, por último, um equipamento/software analisador dos fluxos.
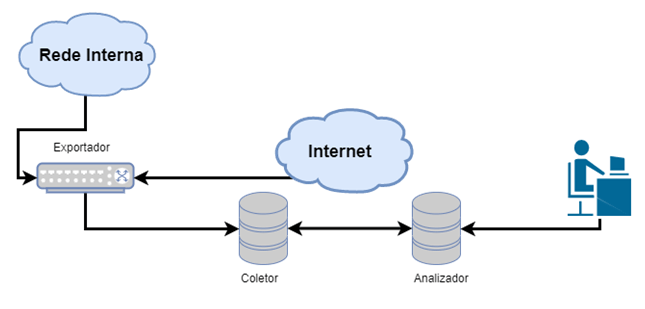
Um flow é exportado quando cumpre certos requisitos: (i) o fluxo se torna inativo, ou seja, nenhum novo pacote relacionado a esse flow é recebido até atingir o timeout (que é configurável); (ii) o flow ainda está tramitando pacotes, porém atinge o timeout estabelecido; (iii) algo na comunicação indica que ela foi terminada, por exemplo, flags TCP do tipo FIN ou RST.
Após isso, os flows são transmitidos ao coletor, que é normalmente um equipamento centralizador para vários exportadores. Essa transmissão costuma ser feita via UDP, porém os equipamentos mais modernos têm capacidade de transmitir via TCP para agregar algum controle, o que pode trazer algum impacto em relação ao desempenho do dispositivo.
O coletor também armazena esses flows para análise posterior via software, analisador dedicado, SIEM etc. Ao final da exportação, o que temos para analisar são os conjuntos de metadados das comunicações, que tipicamente incluem: endereços e portas de origem e destino (quando se trata de comunicações TCP ou UDP), Type of Service, timestamps de início e fim da comunicação, informações sobre as interfaces de entrada e saída do equipamento, flags TCP e protocolo encapsulado (tipo de dado tramitando, seja TCP ou UDP), informações sobre protocolos de roteamento como BGP (next-hop, AS de origem, AS de destino...). A tabela abaixo mostra os campos presentes no cabeçalho do protocolo netflow V5.
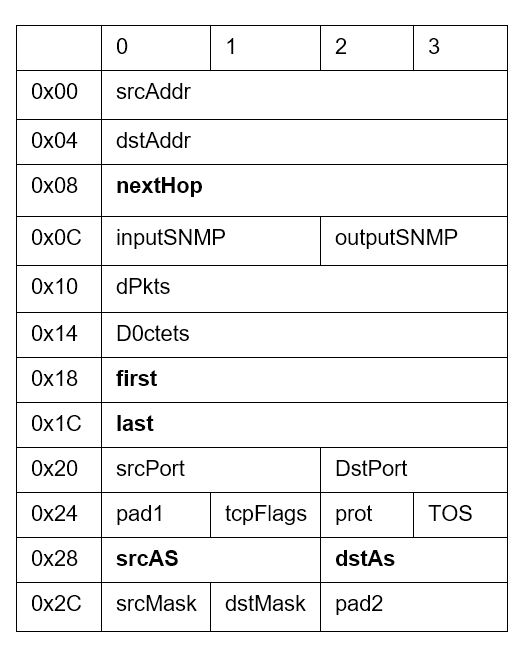
Ok, mas por que os dados de flows são úteis?
Os dados de fluxo são um importante aliado porque mostram, a um custo baixo, um resumo estatístico das comunicações que tramitam pelos exportadores. Por isso existe a necessidade de uma boa estratégia para escolher boas posições de exportação, ou seja, selecionar os equipamentos com maior potencial de visibilidade (firewalls, switches, roteadores). A depender da ferramenta escolhida para realizar a análise, (e há várias, tanto open source quanto comerciais) é possível enxergar coisas como:
• Estatísticas de tráfego divididas por aplicação; protocolo; domínio; IP e porta de origem e destino;
• Resumo estatístico (Top N) de endereços, comunicações e até Autonomous Systems (AS);
• Resumo estatístico das informações descritas acima com enriquecimento pelas ferramentas de análise de flow¸ ou pelo SIEM, como Geolocation e outros.
Esse tipo de informação ajuda a entender questões sobre a infraestrutura da organização. É possível descobrir se existem aplicações proibidas sendo executadas; encontrar gargalos ou equipamentos com defeito; descobrir anomalias de excesso ou consumo exagerado de banda por algum equipamento; entender conexões estranhas a endereços de países com alto índice de ataques cibernéticos, assim como ASs com má reputação; comunicação com servidores de comando e controle, entre outras coisas.
Novamente: os dados de flow não agregam o conteúdo das comunicações. Pensando nisso, um analista que dispõe apenas dessas informações deve sempre associar alguns fatores para obter inteligência desse tipo de metadado. A mesma observação se aplica aos dados criptografados, mesmo onde o tráfego é completamente capturado. Essa associação de fatores pode ser feita pensando:
1. Na direcionalidade do tráfego – saber qual deveria ser a direção típica da conversa entre cliente e servidor, por exemplo: é legítimo que um servidor X da rede DMZ acesse um qualquer serviço na internet na porta 1234?
2. No tráfego esperado associado ao protocolo envolvido na comunicação – conhecendo bem o funcionamento de certos protocolos, é possível ter uma ideia se o tráfego deveria ter uma duração maior ou menor, uma quantidade de dados maior ou menor, e a partir disso encontrar anomalias;
3. Em análises baseadas no tempo – para identificar picos de tráfego que podem indicar transferência de arquivos, ou comunicações estranhas que podem se referir a respostas a comandos;
Associando esses fatores é possível criar baselines de monitoramento para, através das estatísticas disponibilizadas pelos flows, saber, por exemplo, se uma conexão SSH (normalmente porta 22/tcp) com duração rápida demais, ou se uma conexão HTTP (porta 80/tcp) demorada demais são acessos legítimos ou são possíveis ataques. A tabela abaixo mostra exemplos de observações que podem ser feitas associando os fatores descritos
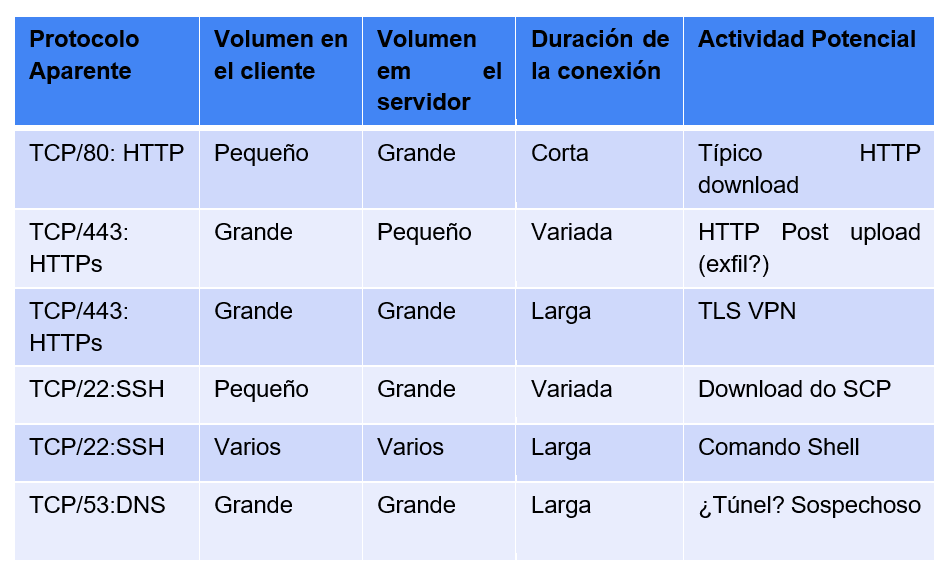
Os dados de flow também podem ser uma boa alternativa para tráfego criptografado, quando a organização não dispõe de inspeção de TLS/SSL: isso se mostra útil porque, caso não exista a capacidade de inspecionar tráfego criptografado, uma captura completa desse tipo de tráfego se torna um enorme desperdício de recursos, principalmente quando falamos de armazenamento.
Estratégias de captura
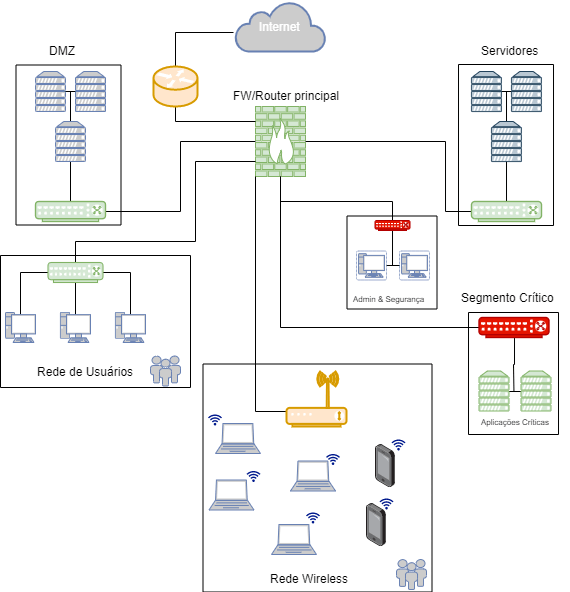
Na estrutura acima, há vários locais onde os dados podem ser coletados. Honestamente, qualquer ponto de agregação da rede é um ótimo candidato à captura, tanto completa quanto somente dos flows. O primeiro ponto a ser observado é que há diferentes níveis de criticidade e valor dos dados. Ao entender estes, juntamente com os volumes de dados produzidos em cada segmento, a organização pode planejar uma solução de captura.
Como sugestão, os potenciais pontos de agregação do cenário acima estão diferenciados por cores.
• Na cor verde, pontos de exportação de flow;
• na cor vermelha, pontos onde pode ser necessária a captura completa; e,
• Em âmbar, pontos que contêm muita informação e são candidatos à exportação de flow, porém, com menor prioridade.
Se você ainda está numa fase de planejamento da captura dos dados, ou se pretende realizar uma reestruturação do projeto de captura na sua infraestrutura, os passos a seguir podem dar uma noção do que fazer.
1: Identificar os dados críticos
Capturar o tráfego completo está longe de ser uma estratégia barata para a maioria das organizações (se você tem condições para isso, sinta-se privilegiado!). O primeiro passo que podemos tomar é identificar quais são os dados mais críticos da organização para definir a melhor estratégia para a visibilidade desses dados. Para esses dados e os ativos que os armazenam ou nos quais eles trafegam, você provavelmente vai precisar de captura completa.
2: Entender a sua rede
Parece óbvio, mas precisa ser dito: muitas organizações não têm conhecimento, mesmo que em alto nível dos seus sistemas e equipamentos (por exemplo: S.O e IP de todos os ativos). Uma boa estratégia pode ser começar mapeando os caminhos a partir dos dados críticos para a Internet e para os sistemas desktop dos administradores que controlam esses dados.
3: Identificar pontos de estrangulamento e pontos críticos da rede
Conhecendo bem a rede, é possível identificar os pontos onde várias sub redes ou VLANs se encontram e considerar o nível ideal de captura de dados. Em seguida, identificar as redes críticas que operam com switches e roteadores e verificar suas capacidades de captura. Estes dispositivos estão entre usuário e dados e a Internet (se os sistemas forem capazes de se conectar à Internet).
4: Identificar centros de gravidade críticos
Encontrar no ambiente, locais que possuem altas concentrações de determinado objeto: dados críticos! Ao definir estes centros, a organização está pensando no que é realmente importante em termos de proteção. Entretanto, os centros de gravidade críticos incluem coisas diferentes, dependendo do tipo de negócio.
A seguir, alguns exemplos:
• Repositórios de código fonte (empresas de software)
• Sistemas contábeis (setor financeiro e empresas de capital aberto)
• Sistemas administradores de sistemas (tendem a conter planos, senhas, diagramas e software)
• Aplicações web desenvolvidas internamente usando credenciais (AD, LDAP)
• Servidores DNS
5: Planejar os exportadores de flow e pontos de captura completa
Em locais de alto volume de tráfego, como gateways de Internet, é mais interessante capturar os fluxos de dados. Em pontos críticos de estrangulamento de dados e dispositivos de rede críticos, pode ser interessante implementar as duas abordagens: tanto fluxos quanto a captura completa.
6: Verificar requisitos de conformidade
Dados de flow podem ajudar a cumprir requisitos de conformidade de registros, porém é necessário verificar junto à norma se eles são suficientes, e em quais pontos esses metadados podem ser usados para cumprir algum requisito.
Conclusão
Apesar de todas as vantagens, capturar flow não é uma bala de prata e não vai resolver todos os problemas de monitoramento da organização e traz consigo alguns inconvenientes, como por exemplo:
• é possível identificar os equipamentos, mas é necessário fazer análises e associações para descobrir os usuários envolvidos com aquele tráfego;
• NATs podem tornar a captura inconsistente, porque o flow é gravado no exportador, portanto é necessário observar isso na hora de configurá-lo;
• Não custa repetir: não é possível ver o conteúdo da comunicação através flows.
Nesse sentido, é sempre importante equilibrar, variar as abordagens e considerar as diversas possibilidades para melhorar a segurança e gerenciamento de uma maneira geral. Dados de fluxo são apenas mais um dos grandes aliados para proteção de infraestruturas.
Finalizando o raciocínio, os flows são poderosos para monitoramento de qualquer rede e fornecem grande visibilidade da infraestrutura a baixo custo, justamente porque grande parte das organizações já possui ativos capazes de exportá-los, tanto em ambientes predominantemente on-premise quanto em ambientes de cloud ou híbridos: fornecedores como AWS e GCP disponibilizam os dados de fluxo para o cliente. Frequentemente, o que falta é simplesmente ativar a exportação dos flows e apontar para um coletor/analisador. Para o caso de não existirem coletores/analisadores disponíveis na organização, criar uma estrutura para análise é relativamente simples e barato. Compra de hardware extra raramente é necessária.