


BY:
Felipe Alves
CYBER SECURITY RESEARCHER & TRAINER
SHARE
REFERENCES
B. Claise, B. Trammell, and P. Aitken, “Specification of the IP Flow Information
Export (IPFIX) Protocol for the Exchange of Flow Information,” RFC 7011 (Internet
Standard), Internet Engineering Task Force, September 2013. [Online]. Available: http://www.ietf.org/rfc/rfc7011.txt
What is NetFlow? An Overview of the NetFlow Protocol. Disponível em: https://www.kentik.com/kentipedia...
Why use flow data for monitoring?
At the point where we are located in the growing curve of technological
evolution and, consequently, of digital threats, the need for visibility into the data that
is passing through the infrastructures of various types of organizations is growing at the
same intensity. The demand for this visibility may come up against several technical
aspects, ranging from the need for good strategies for positioning the capture equipment to
the need for large amounts of hardware to store and process the captured data. Another item
that needs attention is the value that the captured data has, that is, it is important to
know if what is being stored actually brings the desired visibility and monitoring capacity.
From these ideas, some questions naturally arise, and in Blue Teamers discussion circles,
questions that are always present are: what should I capture? Capture all the traffic for
less time (due to hardware limitations)? Capture only the metadata and make correlations
with the available logs? To answer these questions, only a good cliché: You have to work
with balance, because both approaches bring visibility and have advantages and
disadvantages.
At first one might think that the ideal scenario is to have the traffic completely captured
to support incident response activities, threat hunting, SOC, CSIRT, etc., since through the
complete capture it is possible to reconstruct the communication between client and server
and get a real picture of what happened, but while this might really seem like the best of
worlds for investigations, the historical amount available will not go beyond a few days or
weeks due to the large amount of resources required. This becomes a problem when we need to
investigate something that occurred in a period before the historical capacity, without
considering the problems that can arise when dealing with encrypted traffic. A balanced
alternative is to get metadata of this traffic integrated with logs, which can cover a good
part of the organization in relation to statistics about the connections made between the
users of the infrastructure.
In this context, the purpose of this article is to discuss the second option mentioned in
the previous paragraph, which is an interesting approach to full traffic capture and is able
to deliver good visibility on issues such as: who is communicating with whom, when this
communication occurred, for how long and how often. It is about capturing data flows,
exporting them, and creating monitoring metrics based on these flows, using protocols such
as the one Cisco originally named NetFlow, which was later "translated" to an opensource
version that was named IPFIX. This kind of approach can be highly beneficial for the ongoing
monitoring of an organization, as it makes it possible to maintain much greater historical
traceability over communications simply because it requires less storage resources when
compared to full traffic capture.
This is the first in a series of two posts on this subject. In it we will define some
concepts and reflect on monitoring strategies, and in another moment we'll cover tools,
techniques, and practical demonstrations.
What is Netflow/Dataflow/Flow?
Looking for the information straight from the source, the 2013 RFC 7011 which specifies the
IPFIX protocol, defines data flow, or simply flow, as the following: "a set of IP packets
passing through an observation point within the network during a certain time interval, with
all packets belonging to a particular flow having a set of properties in common."
The properties of flows, also called flow-keys are each field that: (i) belong to the packet
header itself; (ii) are properties of the packet, such as the size in bytes; (iii) are
derived from the Packet Handling activity, such as the Autonomous System Number (ASN).
In short, each flow is a set of aggregated packets, i.e. the packets are not considered
individually, as in a full capture approach. It is as if the packet sequences have a kind of
signature that is used to join the various elements of a communication into a single flow.
The flows contain valuable metadata about the communications and must be exported by some
equipment that the traffic passes through, called an 'exporter' (usually firewalls, switches
and routers), and collected for later analysis.
Also according to the RFC, the collection of this flow is for administrative purposes or any
others, such as those mentioned at the beginning of this publication, like visibility, but
also troubleshooting, threat detection, performance monitoring and, consequently, security!
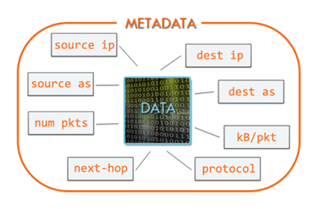
Metadata
As mentioned earlier, a flow exporter identifies a flow as a set of packets with common
characteristics belonging to a given communication. These characteristics contained in the
packets are at a minimum: port of the incoming interface, source and destination IP
addresses, source and destination ports, protocol and service type. Interestingly these can
also be considered as the main attributes of the communication that will be useful for
further analysis, always remembering that this is metadata, i.e.: the content of the packets
is not available. We will talk about this later.
Export
The flow capture and analysis processes basically depend on 3 components: an "exporter"
equipment; a "collector" equipment; and finally, a flow analyzer equipment/software.
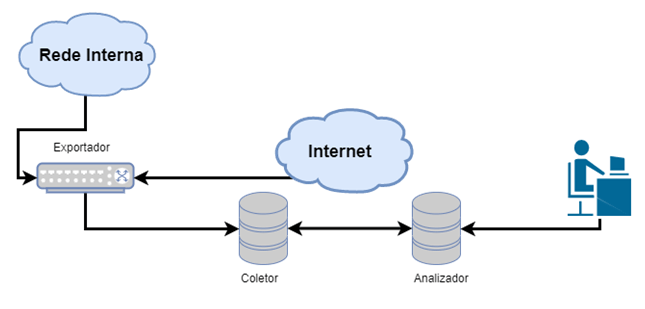
A flow is exported when it meets certain requirements: (i) the flow becomes inactive, that
is, no new packets related to this flow are received until it reaches the timeout (which is
configurable); (ii) the flow is still processing packets, but reaches the established
timeout; (iii) something in the communication indicates that it has been terminated, for
example, TCP flags of the type FIN or RST.
After that, the flows are transmitted to the collector, which is usually a centralizing
device for several exporters. This transmission is usually done via UDP, but the most modern
equipment is capable of transmitting via TCP to add some control, which can have some impact
on the device’s performance.
The collector also stores these flows for later analysis via software, dedicated analyzer,
SIEM, etc. At the end of the export, what we have to analyze are the communication metadata
sets, which typically include: source and destination addresses and ports (when it comes to
TCP or UDP communications), Type of Service, start and end timestamps of the communication,
information about the equipment's input and output interfaces, TCP flags and encapsulated
protocol (type of data being transmitted, either TCP or UDP), information about routing
protocols such as BGP (next-hop, source Autonomous System, destination Autonomous
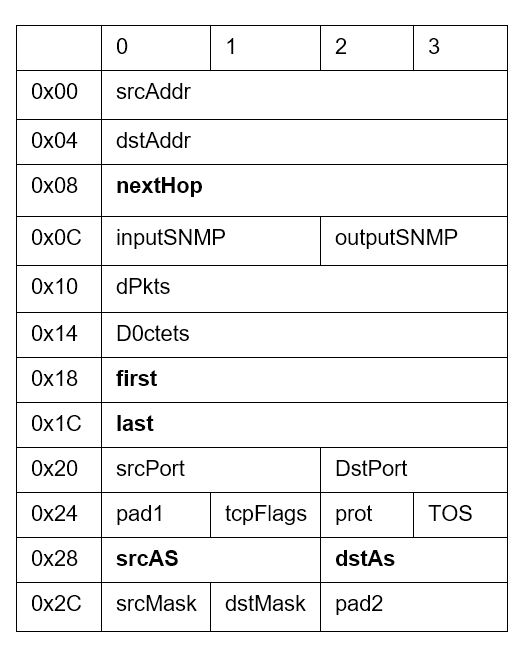
System...). The table below shows the fields present in the netflow V5 protocol header.
Ok, but why is flow data useful?
Flow data is an important ally because it shows, at a low cost, a statistical summary of the
communications that pass through the exporters. This is why there is a need for a good
strategy to choose good export positions, i.e. to select the equipment with the greatest
potential for visibility (firewalls, switches, routers). Depending on the tool chosen to
perform the analysis, (and there are several, both open source and commercial) it is
possible to see things like:
• Traffic statistics broken down by application; protocol; domain; source
and destination IP and port;
• Statistical summary (Top N) of addresses, communications, and even
Autonomous Systems (AS);
• Statistical summary of the information described above with enrichment
by flow¸ analysis tools or by SIEM, such as Geolocation and others o por SIEM, como
Geolocalización y otras
This type of information helps to understand questions about the organization's
infrastructure. It is possible to find out if there are forbidden applications running; find
bottlenecks or malfunctioning equipment; discover anomalies of excess or exaggerated
consumption of bandwidth by some equipment; understand strange connections to addresses in
countries with high rates of cyber attacks, as well as ASs with a bad reputation;
communication with command and control servers, among other things.
Again: the flow data does not aggregate the content of the communications. With this in
mind, an analyst who only has this information should always combine some factors to get
intelligence from this kind of metadata. The same observation applies to encrypted data,
even where traffic is completely captured. This association of factors can be done by
thinking:
1. On traffic directionality - knowing what the typical direction
of the conversation between client and server should be, for example: is it legitimate for
an X server in the DMZ network to access any service on the Internet on port 1234?
2. In the expected traffic associated with the protocol involved in
the communication - knowing well how certain protocols work, it is possible to get an idea
of whether the traffic should have a longer or shorter duration, a larger or smaller amount
of data, and from this to find anomalies;
3. In time-based analysis - to identify traffic spikes that may
indicate file transfers, or strange communications that may refer to responses to
commands;
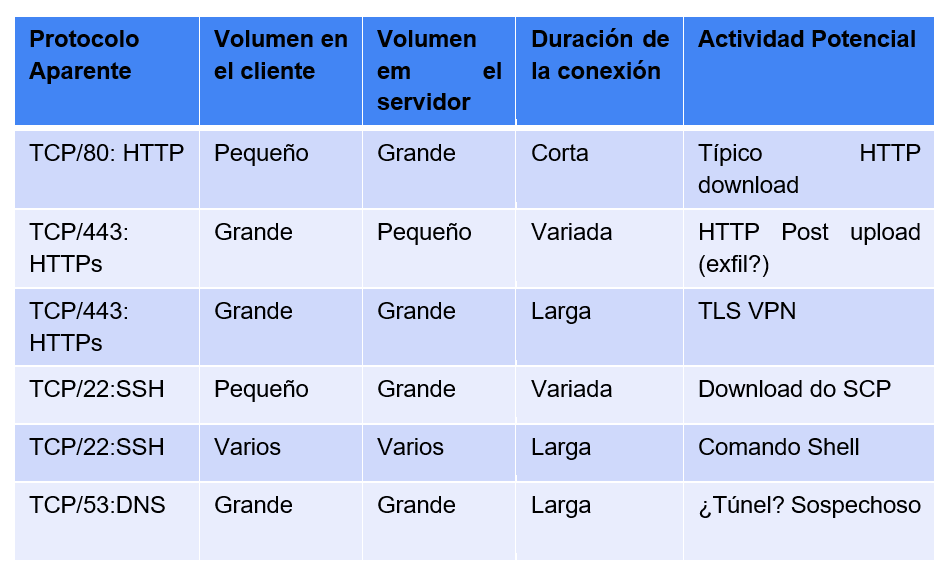
By associating these factors it is possible to create monitoring baselines in order, through
the statistics made available by flows, to know, for example, if an SSH connection (usually
port 22/tcp) that lasts too long is legitimate or if an HTTP connection (port 80/tcp) that
takes too long is a possible attack. The table below shows examples of observations that can
be made associating the factors described.
Flow data can also be a good alternative for encrypted traffic when the organization does
not have TLS/SSL inspection: this is useful because if the capability to inspect encrypted
traffic does not exist, a full capture of such traffic becomes a huge waste of resources,
especially when it comes to storage.
Capture Strategies
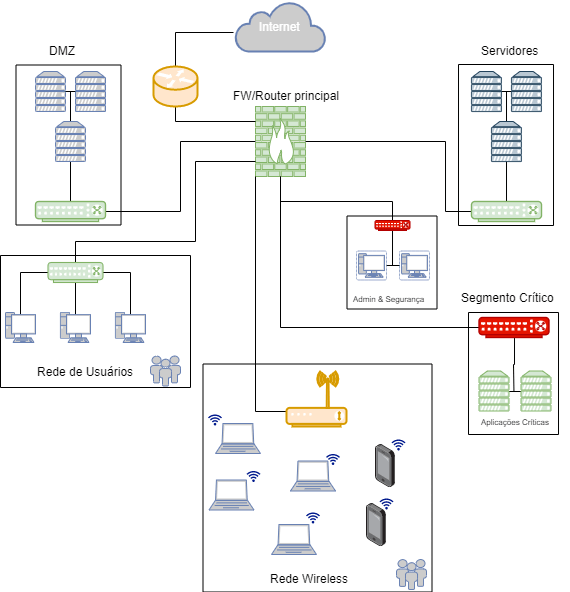
In the framework above, there are several places where data can be collected. Honestly, any
aggregation point in the network is a great candidate for capturing either complete or just
the flows. The first point to note is that there are different levels of criticality and
value of the data. By understanding these, along with the volumes of data produced in each
segment, the organization can plan a capture solution.
As a suggestion, the potential aggregation points in the above scenario are differentiated
by colors
• In green, flow export points.
• In red color, points where complete capture may be required.
• In amber, points that contain a lot of information and are candidates
for flow export, but with lower priority.
If you are still in a data capture planning phase, or if you are planning a capture project
restructuring in your infrastructure, the following steps can give you a sense of what to
do.
1: Identify the critical data
Capturing full traffic is far from a cheap strategy for most organizations (if you can
afford it, feel privileged!). The first step we can take is to identify what the
organization's most critical data is in order to define the best strategy for the visibility
of that data. For that data and the assets that store it or on which it travels, you will
probably need a complete capture.
2: Understand your network
It seems obvious, but it needs to be said: many organizations do not have even high-level
knowledge of their systems and equipment (e.g. O.S. and IP of all assets). A good strategy
might be to start mapping the paths from critical data to the Internet and to the desktop
systems of the administrators who control that data.
3: Identify bottlenecks and critical points in the network
By knowing the network well, you can identify the points where various subnets or VLANs meet
and consider the optimal level of data capture. Next, identify the critical networks that
operate switches and routers and verify their capture capabilities. These devices stand
between user and data and the Internet (if the systems are capable of connecting to the
Internet).
4: Identify critical centers of gravity
Finding in the environment, places that have high concentrations of a certain object:
critical data! By defining these centers, the organization is thinking about what is really
important in terms of protection. However, critical centers of gravity include different
things, depending on the type of business
The following are some examples:
• Source code repositories (software companies)
• Accounting systems (financial sector and publicly traded companies)
• System administrators (tend to contain plans, passwords, diagrams, and
software)
• Internally developed web applications using credentials (AD, LDAP)
• Internally developed web applications using credentials (AD, LDAP)
5: Plan the flow exporters and full capture points
In high traffic volume locations, such as Internet gateways, it is more interesting to
capture data flows. At critical data bottlenecks and critical network devices, it may be
interesting to implement both approaches: both flows and full capture.
6: Check compliance requirements
Flow data can help meet record compliance requirements, but it is necessary to check with
the standard to see if it is sufficient, and at what points this metadata can be used to
meet any requirements.
Conclusion
Despite all the advantages, capturing flow is not a silver bullet and will not solve all the
organization's monitoring problems and brings with it some drawbacks:
• It is possible to identify the equipment, but it is necessary to do
analysis and associations to find out the users involved with that traffic.
• NATs can make the capture inconsistent, because the flow is recorded in
the exporter, so you need to observe this when setting it up.
• It bears repeating: you cannot see the content of the communication
through flows.
In fact, it is always important to balance, vary approaches, and consider the various
possibilities for improving overall security and management. Flow data is just one more of
the great allies for infrastructure protection.
To conclude, flows are powerful for monitoring any network and provide great visibility into
the infrastructure at low cost, precisely because most organizations already have assets
capable of exporting them, both in predominantly on-premise and in cloud or hybrid
environments: vendors like AWS and GCP make flow data available to the customer. Often, what
is missing is simply enabling the export of the flows and pointing to a collector/analyzer.
In case there are no collectors/analyzers available in the organization, creating a
framework for analysis is relatively simple and inexpensive. Buying extra hardware is rarely
necessary.